
Today, we're announcing that we've improved a feature that brings together modern tools, applies those tools to a well-scoped problem for which they are adequately suited, and reduces friction within your team's development lifecycle! It did those things before, but now you can talk to it!
Our CI/CD Review AI feature is now conversational, and ready to be your new interactive assistant for debugging.
What does it do?
The CTO.ai platform was built to reduce friction within your software development lifecycle by helping you shape a Developer Experience that grows with the evolving needs of your team. All of our Review AI features are meant to enhance your Developer Experience, helping you rapidly identify potential issues within your code changes and pipeline failure logs—often before anyone else on your team even notices you requested a review.
With its new conversational abilities, our CI/CD Review AI bot can act as your debugging muse. A rubber duck that talks back, if you will. A chatty… drop of grease to get your gears unstuck?
Stochastic models have failure modes that are impossible to predict or prevent—and the complex cloud environment that underlies your mission-critical infrastructure is the last place you want to introduce additional opportunities for stochastic failure. That’s why we built a CI/CD Review AI!

By applying LLMs in a way that takes advantage of their exceptional ability to extract and present the most salient details from the type of loosely-structured mess of text often encountered in the real world, we’re helping your team reduce the time and effort required to identify problems—all without giving an unpredictable statistical model control over your business-critical data or infrastructure.

How does it work?
As with our other Review AI features, to use our CI/CD Review AI, connect your GitHub account to the CTO.ai platform, then add the CTO.ai Review label to your Pull Request to get started. Adding this label will trigger our Review AI bot to begin its first-pass review of your code changes and to watch for any failed Pipelines runs associated with the Pull Request.
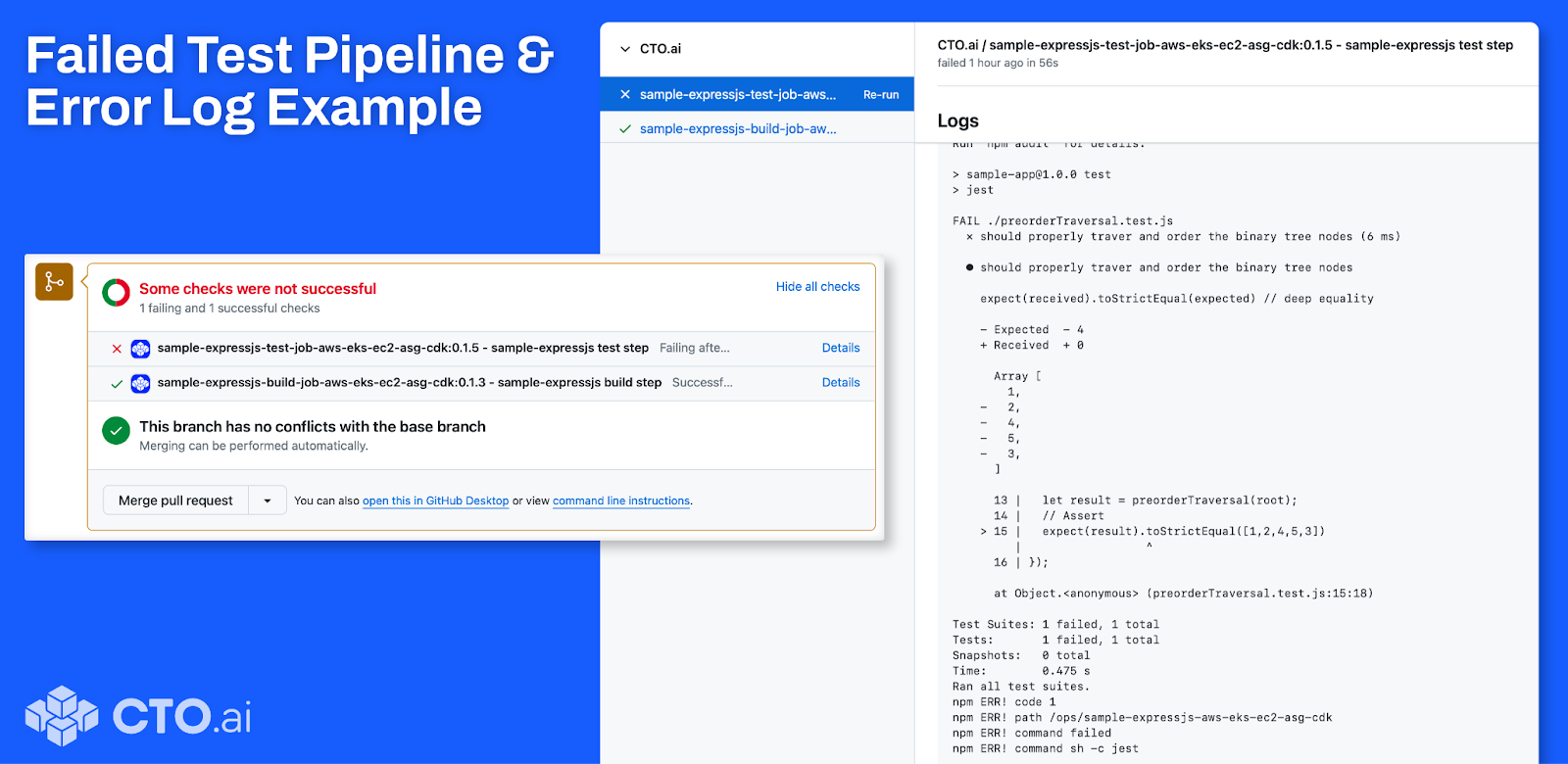
In the event that your Pipeline fails—regardless of whether the cause is a failed test job, an inability to build your container’s image, or some other issue that leads the Pipeline to exit with a non-zero exit code—our CI/CD Review AI rapidly extracts the relevant details from the error logs, then automatically proposes a potential path toward resolution as a review comment, posted directly on the file in question:
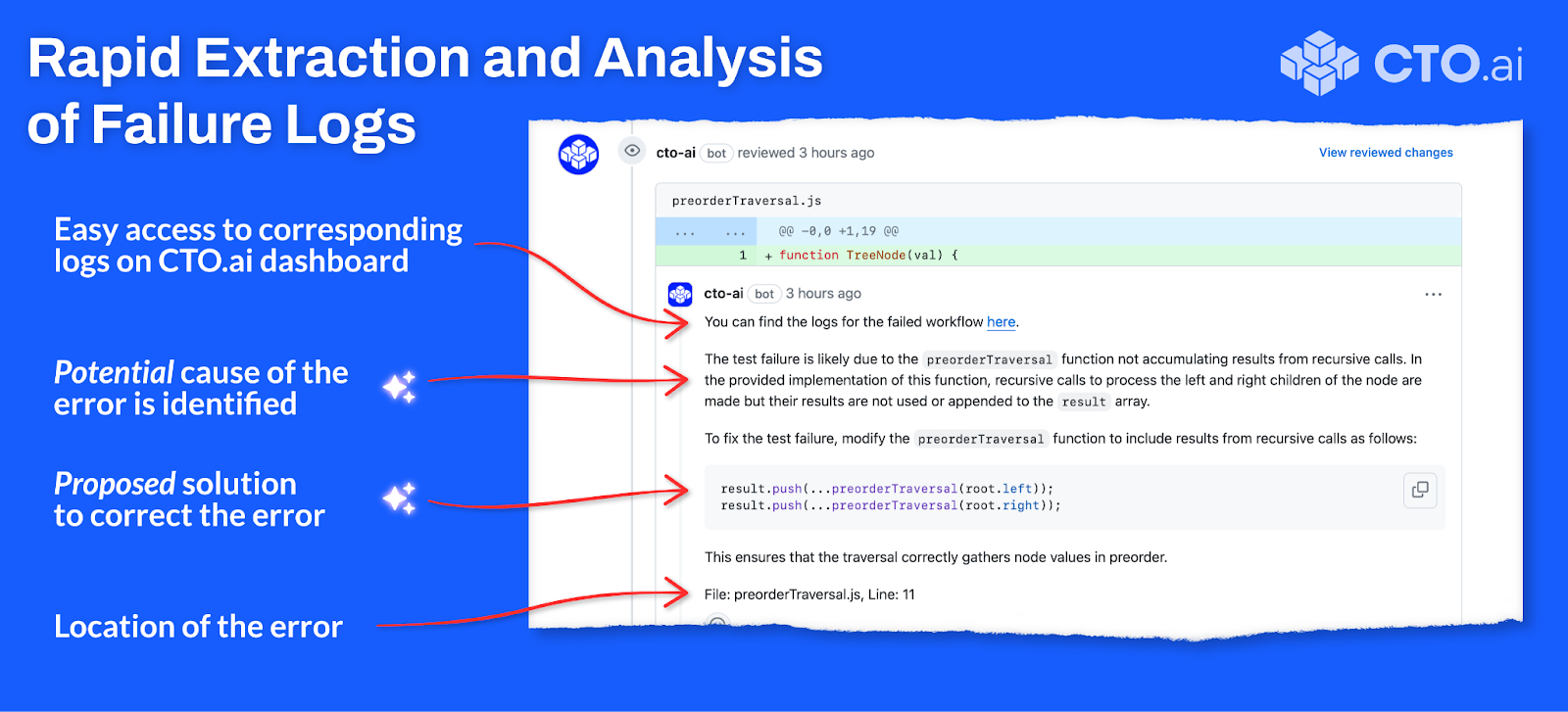
These are the potential cause and the proposed solution to the identified problem; that is, they’re suggestions. I have yet to see an example of a response from our Review AI that inaccurately describes the problem, but this is still text being produced by a stochastic model—there is vast potential for failure modes that we are unable to foresee.
The conversational abilities of our Review AI are particularly useful for understanding why seemingly-inaccurate responses may be produced, as off-topic output is often an indicator of subtle errors in a codebase influencing which patterns the model deems the most salient. An LLM can never be confused—apparent errors are merely the model’s transformation of the input failing to conform to the user’s expectations of the output!
Don't get me wrong, as a psycholinguist by training, I love LLMs for exactly what they are: massive computational models which embed the incomprehensibly complex and overlapping statistical relationships that exist within human (and computer) languages. I know I won't find any new ideas in an LLM—only my own input, filtered through a stochastic transformer, and arranged in a quasi-unique way that makes the output feel fresh!
Of course, that’s the fundamental nature of LLMs! Because these models are derived from an unprecedented, mind-bogglingly-huge corpus of publicly-available text, LLMs are, in a sense, a compressed, extremely lossy representation of every idea available on the public-facing internet.
Thus, we are only implementing LLMs in a way that provides guidance for the humans on your team: For a given codebase, the pathways that can lead to a specific error being raised are limited, but there are infinite possibilities for introducing new issues.
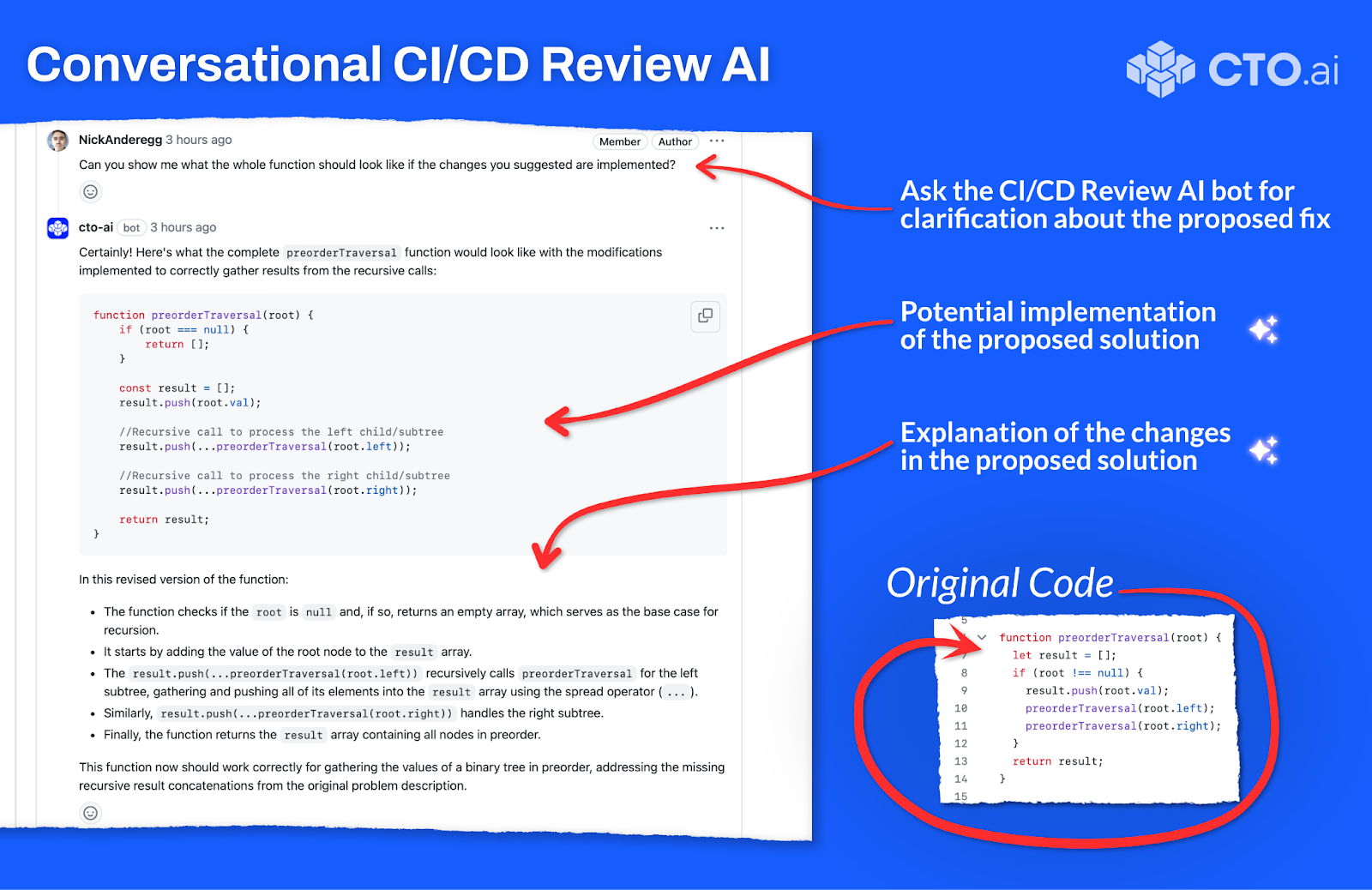
If our Review AI provides feedback that is unclear, fails to solve the whole problem, or is simply more complicated than you were expecting, the conversational features make it easy to quickly find clarity!
Want to see this feature in action? Book a feature demo with one of our experts today!
Comments